Abstract
Siamese-based visual tracking methods generally execute the classification and regression of the target object based on the similarity maps. However, existing works either solely employ a single map generated by the last convolutional layer which degrades the localization accuracy, or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. In this work, we propose an efficient and effective hierarchical feature transformer (HiFT) in Siamese tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into a feature transformer network. Not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can learn the inter-dependencies among multi-level features, and discover a tracking-tailored feature space with strong discriminability due to the interactive fusion of spatial (early layers) and semantics cues (deep layers). Comprehensive evaluations on aerial benchmarks have proven the effectiveness of HiFT, and the real-world tests on the aerial platform have validated its practicability and robustness with a real-time speed.
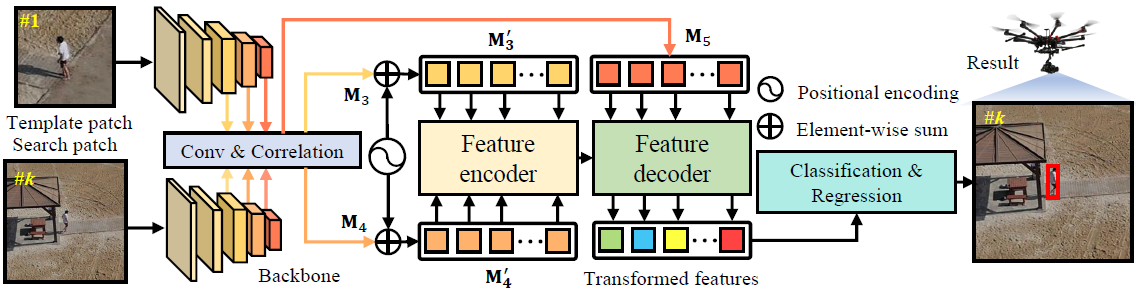 Fig. 1 Overview of the HiFT tracker.
Fig. 1 Overview of the HiFT tracker.
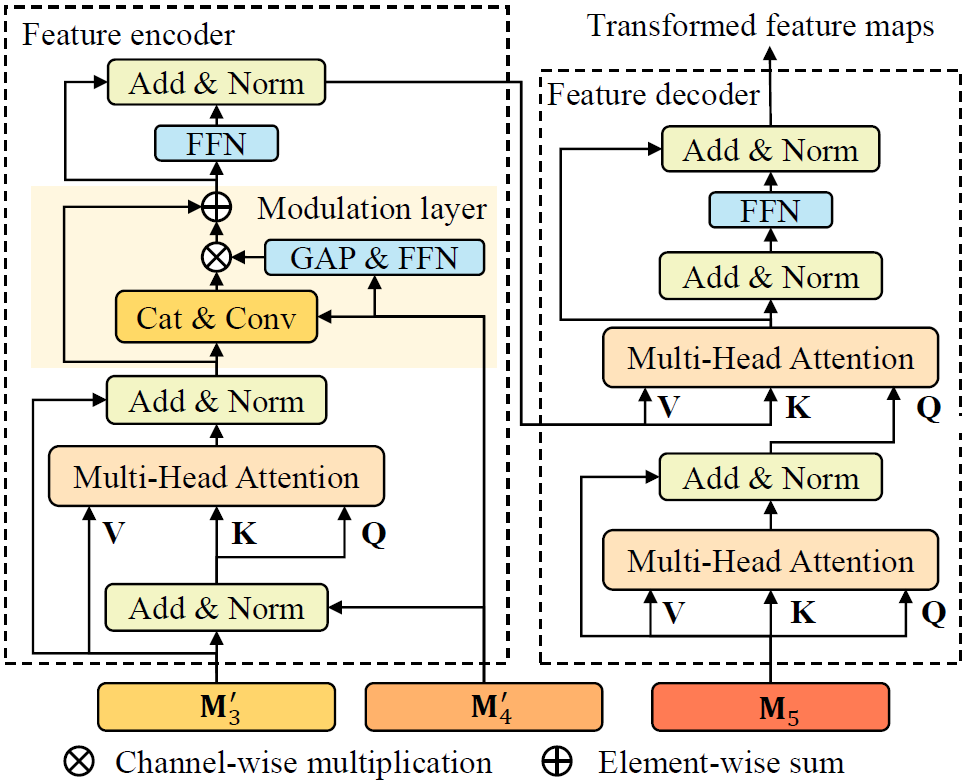 Fig. 2 Framework of the hierarchical feature transformer.
Fig. 2 Framework of the hierarchical feature transformer.